

In 1950 Watson and Crick understood that genetic information is coded in the DNA in the form of a double helix. Their original paper is available at: Watson, J.D. & Crick F.H.C. A Structure of Deoxyribose Nucleic Acid. Nature, 1953. 171:737-738 and earned them a Nobel Prize. James Watson also wrote a book titled “The Double Helix” which provides a highly biased view of the genesis of this discovery, which eulogizes the author and severely underplays the role played by the brilliant chemist Rosalind Franklin, is provided in the book. There is a YouTube documentary called “The Secret of Photo 51” that provides some additional background for the facts about her role in the discovery of the double helix:
Once scientists knew that DNA was the way information was maintained and transmitted, the next question was: How can one read the code? What is the code to translate the DNA sequence into proteins? In other words, “What is the genetic code?” The story of how the genetic code was deciphered is quite fascinating and involved the joint efforts of biologists, biochemists, chemists and physicists. Below I will discuss some of the salient aspects of how the code was deciphered. More information is at:
https://profiles.nlm.nih.gov/spotlight/sc/feature/deciphering
https://en.wikipedia.org/wiki/Nirenberg_and_Matthaei_experiment
https://www.acs.org/content/acs/en/education/whatischemistry/landmarks/geneticcode.html
Knowing who deciphered the code and how they did it is historically important because many people falsely believe that Francis Crick or James Watson deciphered the genetic code. This is incorrect. The major credit for cracking the code goes to Marshall Nirenberg, who discovered the first codon (three letters on DNA that code for an amino acid) in 1961. The complete code was deciphered by 1966 and Nirenberg shared Nobel Prize in Physiology or Medicine in 1968 for his seminal work on the genetic code. He shared the award with Har Gobind Khorana (University of Wisconsin), who mastered the synthesis of nucleic acids, and Robert Holley (Cornell University), who discovered the chemical structure of transfer-RNA. Collectively, the three were recognized “for their interpretation of the genetic code and its function in protein synthesis."

It was known that proteins in organisms were composed of 20 amino acids. Since DNA is a sequence made from 4 nucleotides (A: Adenine, C: Cytosine, G: Guanine and T: Thymine), it was clear that using two nucleotides to code for an amino acid is inadequate. Two nucleotides could only code for 42 = 16 amino acids. At a minimum, each amino acid must be represented by at least 3 nucleotides. Two physicists, George Gamow and Francis Crick, played a key (albeit futile) role in the search for this code. George Gamow was a theoretical physicist and cosmologist, who was intrigued by the challenge of deciphering the code. He believed that the best way to move forward to find the code was through collaborative effort, with the best scientists from different fields sharing their ideas and results. In 1954, he founded the "RNA Tie Club", with the aim of solving “the riddle of the RNA structure and to understand how it built proteins." The club had 20 regular members, one for each amino acid, and four honorary members, one for each nucleotide (see image above). The members all got woolen neckties designed by Gamow with an embroidered green-and-yellow helix. Many prominent scientists were members, eight of whom were or would become Nobel Laureates. Each member was identified by an amino acid. For example, James Watson was PRO for proline, Francis Crick was TYR for tyrosine and Sydney Brenner was VAL for valine.
Here is an image of some of the members:
Gamow’s genetic codes: Gamow came up with an ingenious (but wrong) genetic code, which he published as a paper in Nature: “Gamow, G. Possible relation between deoxyribonucleic acid and protein structures. Nature, 1954. 173, 318.” He proposed an overlapping triplet code. His reason to propose it was that it allows the highest information density, which is much beloved of cryptographers. In his idea, the double stranded helix of DNA acts as a direct template to translate nucleotides amino acids. So, for example, the sequence ATGCTA would contain the triplets ATG, TGC, GCT, CTA each of which would code for a different amino acid. The figure below is from his letter to Watson explaining his idea.
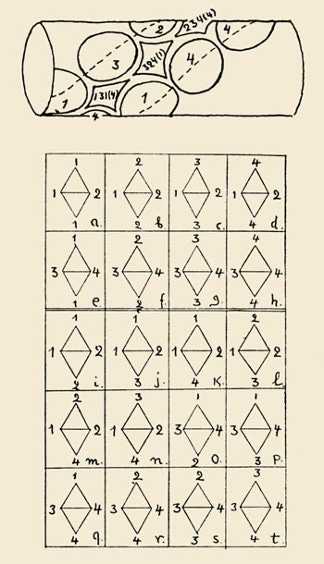
In Gamow's “diamond code”, double-stranded DNA are a direct template for assembling amino acids into proteins. The various combinations of bases along one of the grooves in the double helix form distinctively shaped cavities into which the side chains of amino acids fit and each cavity attracts a specific amino acid. Each of the cavities was bounded by the bases at the four corners of a diamond. When all the amino acids were lined up in the correct order along the grooves, an enzyme would come along to stitch them together.
As shown in the figure above, if the DNA helix is oriented vertically, the bases at the top and bottom corners of a diamond are on the same strand and are separated by a single intervening base; the left and right corners of the diamond are defined by that intervening base and by its complementary partner on the opposite strand. There are 64 possible codons, but not all of them are distinct. Gamow noted that most amino acid side chains are symmetrical, and he therefore postulated that the diamonds could be flipped end-for-end or flopped side-to-side without changing their meaning. For example, the triplet CAG becomes GAC when it is flipped end-for-end, and both of these codons must specify the same amino acid. Flopping CAG side-to-side changes the middle A into a complementary T, so that CTG and GTC are also members of the same family of equivalent codons. When all such symmetries are taken into account, how many distinct codons remain? Gamow counted them up and found the answer is 20—just the magic number he was looking for. In this code, certain amino acids were required to always appear next to each other.
To see more details about how this code gives 20 amino acids and what the restrictions are, look here.
Unfortunately for Gamow, even with the sparse protein sequence data available in the mid-1950s, Crick was able to show that the diamond code was ruled out by the experimental evidence.
Undaunted by this failure, Gamow proposed a "triangle code" that was also overlapping but had different constraints. In this code the 64 possible triplet codons again sorted themselves into 20 families.
Later Gamow suggested yet another overlapping-triplet code with an even simpler description: Each codon is defined entirely by its base composition, ignoring the order of the bases within the codon. Thus ACT, ATC, CAT, CTA, TAC and TCA are all members of the same codon family and specify the same amino acid. Remarkably, the number of codon families in this scheme again turns out to be exactly 20 (see here for details).
Still more overlapping codes came from Gamow and his friends. Richard Feynman also had a hand in working out one idea. Edward Teller proposed another—a fairly funky scheme in which each amino acid is specified by two bases in the DNA and by the previous amino acid. But overlapping codes were coming to the end of their string.
Patterns of mutations were one source of doubt. With an overlapping code, changing a single base in the DNA could alter three neighboring amino acids, but protein sequence data were starting to show instances of single amino acid replacements. It also turned out that there were known patterns of amino acid repetitions that the diamond code could not produce. For example, Sanger had figured out the amino acid sequence of insulin and it showed that any amino acid can sit next to any other. So, the “diamond code” and all overlapping codes were “beautiful but wrong” ideas. Then came a definitive proof. Sydney Brenner analyzed all the known protein sequence fragments and found enough nearest-neighbor correlations to rule out every possible overlapping code.
Crick’s Comma Free Codes: By the later 1950s, there was growing support for the idea of messenger RNA or mRNA, which is a single-strand molecule acting as an intermediary between DNA and the protein-synthesizing machinery. At the same time Crick was formulating the "adaptor hypothesis," the idea that amino acids do not interact directly with mRNA but are carried by small molecules that recognize specific codons. (Today, the adaptor molecules would be called transfer RNA or tRNA.) The codons were by then thought to be non-overlapping triplets of bases.
The process of gene expression was imagined as going something like this. First the appropriate segment of DNA was transcribed into mRNA by like replication. This was thought to be done by blind copying from DNA (with T replaced by U), without regard to the meaning of the sequence. Then the mRNA stretched out in the cytoplasm of the cell with its long row of codons exposed like a sow's nipples. Each adaptor molecule, already charged with the correct amino acid, poked around until it latched onto the right codon. When all the codons were occupied, the amino acids were linked together, and the completed protein was peeled off the template.
The adapter hypothesis seemed highly plausible because it seemed like the kind of chemistry that living organisms do. The non-sequential pattern-matching needed to line up adaptors on the messenger RNA is vaguely like an enzyme-substrate reaction or like the binding of antibody to antigen. And yet there was a serious problem with the vision of piglets suckling on RNA: A piglet might very well wind up between nipples.
Suppose somewhere in a messenger RNA is the partial sequence ... UGUCGUAAG.... (Note that in RNA uracil replaces the thymine of DNA, and so the code is written with U rather than T.) The intended reading is ... UGU, CGU, AAG..., but the RNA molecule has no spaces or commas to indicate codon boundaries. The sequence could equally well be read as ... UG, UCG, UAA, G ... or ... U, GUC, GUA, AG.... Each of these alternatives would have a different meaning. Furthermore, in the suckling-pig model of protein synthesis, adaptor molecules that attached to the messenger RNA in different reading frames might interfere with one another and prevent any protein at all from being produced. To see more details about the code proposed by Crick look here.
The Actual Genetic Code: As experimental tools grew more sophisticated, several research groups gradually pieced together the real code in the mid 1960s. Marshall Nirenberg and Johann H. Matthaei used a "cell-free" system: in a test tube they put together all the things they thought were needed for protein synthesis – RNA template, ribosomes, nucleotides, amino acids, stabilizing agents and energy. Using this system, they made a very simple nucleic acid, composed of a chain of only one single, repeated letter U, the nucleotide uracil. Using this nucleic acid, the system produced a protein that also contained a single letter but now written in the protein language: the amino acid F, phenylalanine. By showing that a strand of U triplets was indeed the template for the amino acid phenylalanine they had cracked the first letter of the code.
While Nirenberg was presenting this result at a conference in Moscow, he got a phone call from Matthaei (still working at the lab back home), who told him that CCC was the template for the amino acid proline, represented by the letter P.
Next, Har Gobind Khorana, at the University of Wisconsin, devised precise and intricate biochemical methods to produce well-defined nucleic acids, long strands of RNA with every nucleotide in exact position. The first one he made was a strand repeating the two nucleotides UCUCUC. This translated into a strand of amino acids, reading serine-leucine-serine-leucine... Similar synthetic RNA experiments were later used to decipher the rest of the genetic code. Robert Holley was a chemist at Cornell University but he learned about protein synthesis during a sabbatical year at Caltech in California. He discovered the special type of nucleic acid called transfer RNA, or tRNA for short. In 1965 Holley was able to work out its exact structure. This was the first time anyone had established the complete chemical structure of a nucleic acid that was biologically active. tRNA turned out to be the missing molecule that Crick had proposed in his ”Adapter Hypothesis” ten years earlier.
In 1968, seven years after the first letter of the code was presented in Moscow, Nirenberg, Khorana and Holley were awarded the Nobel Prize in Physiology or Medicine.
To the dismay of the members of the RNA Tie Club, especially the physicists, the actual code resembled none of their elegant theoretical notions. As the table assigning codons to amino acids was filled in, it became apparent that the magic number 20 held no magic after all. All the clever mathematical contrivances for getting 20 amino acids out of 64 codons turned out to be figments of the human urge to find pattern, not reflections of any natural order. The "extra" codons are merely redundant: Some amino acids have one or two codons, some have four, others have six. Three codons serve as “stop signs” and one as a “start sign.” At first glance the mapping between codons and amino acids appeared arbitrary, even haphazard. To the members of the “RNA Tie Club” the actual code was a great disappointment because it seemed to be a “frozen accident”, just one among many possibilities. It seemed that once a specific code was chosen, any deviation from it was, literally, punishable by death, since the organism using it would not be able to outcompete the ones who did use it.
Why this particular code? Why did nature choose only one code and not several other equally possible ones? There seemed to be no selective reason why one code would have a selective advantage over others. But if there was no selective advantage, why didn’t several codes coexist in different organisms? Crick’s solution was that all organisms on earth descended from a common ancestor, seeded as a bacterial clone derived from a single some extraterrestrial organism. He even suggested that these bacteria were deliberately seeded by some alien intelligence from space, an idea which he called “directed panspermia”.
However, there are in fact overt patterns in the code, suggesting why it may have been chosen from amongst many possibilities, because it is one of the few codes which are best able to resist change from mutations and speed up evolution at the same time! To read more about this, you should read the chapter on “DNA” in the excellent book by Nick Lane entitled: “Life Ascending, the Ten Great Inventions of Evolution.” You might also want to read the paper: Freeland SJ and Hurst LD, ‘The genetic code is one in a million’, Journal of Molecular Evolution, 1998, 47:238-48.